有了智谱AI“清影(Ying)”,李白都得来给我写首诗
发布日期:2024-09-19 22:14
来源类型:郝富贵 | 作者:赵缩手
| 【494949澳门今晚开什么】 【2024新澳免费资料】 【管家婆一肖一码澳门码资料】 | 【澳门金牛版正版资料大全免费】 【新澳开奖记录今天结果】 【2024年新澳门王中王资料】 【管家婆最准一肖一码】 【新澳彩开奖结果查询】 【2023资料免费大全】 【4949澳门免费资料大全特色】 【2024今晚澳门特马开什么号】 【新澳开奖记录今天结果】 【2O24澳彩管家婆资料传真】
信息有四种主要形式,文字、语音、图片、视频,并且其承载的信息量是在递增的。目前,以ChatGPT为代表的大模型应用产品,主战场还是在文字领域。如果能够攻克视频生成,其价值必然更大。然而,即使是Sora,也只是向我们展示了一种可能性,还远没到大规模商用的阶段。并且,作为OpenAI发布的视频生成模型,绝大部分中国用户是用不上的。我们亟需要有一款国产的视频生成产品,来满足大众的期待。
7月26号,智谱AI就发布了这样一款产品——清影(Ying)。用户只需要输入一段文字,就能快速生成一段充满想象力的视频。并且,用户可以选择自己想要生成的风格,包括卡通3D、黑白、油画、电影感等,配上清影自带的音乐。
需要指出的是,清影是现货,而不是期货。目前,清影已经上线智谱AI的清言App,面向所有用户开放。
让我们玩起来!
作为一个大模型发烧友,有这样一款新奇的产品,当然是要第一时间去尝尝鲜。我急切的登录上自己的智谱清言账号,发现真的把视频生成功能更新上去了。
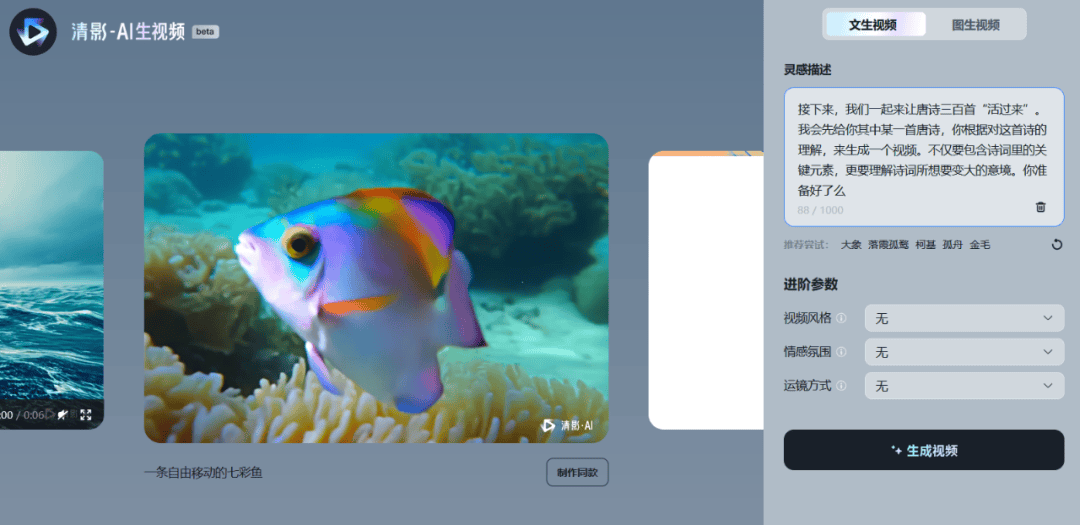
在文生视频功能下,用户可以根据自己的喜好,来设置一些参数,包括:视频风格、情绪氛围、运镜方式。

并且,当视频生成好了之后,用户还可以根据自己的需要,为视频配一段音乐。
接下来,我们要怎么玩呢?
作为一个文艺青年,我脑海里闪现出了唐诗三百首。诗词作为中华文化的瑰宝,如果和大模型这样的前沿科技结合起来,估计会是一件挺有趣的事情。而且,诗词都比较简短,用词精炼,在短短几句中蕴含了丰富的思考、情绪和意境。作为视频生成模型的“考题”,再合适不过了。
说干就干,接下来我们就用几首唐诗来考考清影。
先用李白的《静夜思》来小试牛刀。
《静夜思》
作者:李白
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
接着,我们再来试一首。
《江雪》
作者:柳宗元
千山鸟飞绝,万径人踪灭。
孤舟蓑笠翁,独钓寒江雪。
上面两首诗都有点悲凉,接下来让我们来首欢快一点的。
《春晓》
作者:孟浩然
春眠不觉晓,处处闻啼鸟。
夜来风雨声,花落知多少。
接下来,上点难度。目前,智谱清言的视频生成功能,最多支持1000字。那我们就用长一点的诗歌来考考它,李白的《将近酒》是一个不错的选择。
《将进酒·君不见》
作者:李白
君不见,黄河之水天上来,奔流到海不复回。
君不见,高堂明镜悲白发,朝如青丝暮成雪。
人生得意须尽欢,莫使金樽空对月。
天生我材必有用,千金散尽还复来。
烹羊宰牛且为乐,会须一饮三百杯。
岑夫子,丹丘生,将进酒,杯莫停。
与君歌一曲,请君为我倾耳听。
钟鼓馔玉不足贵,但愿长醉不愿醒。
古来圣贤皆寂寞,惟有饮者留其名。
陈王昔时宴平乐,斗酒十千恣欢谑。
主人何为言少钱,径须沽取对君酌。
五花马,千金裘,呼儿将出换美酒,与尔同销万古愁。
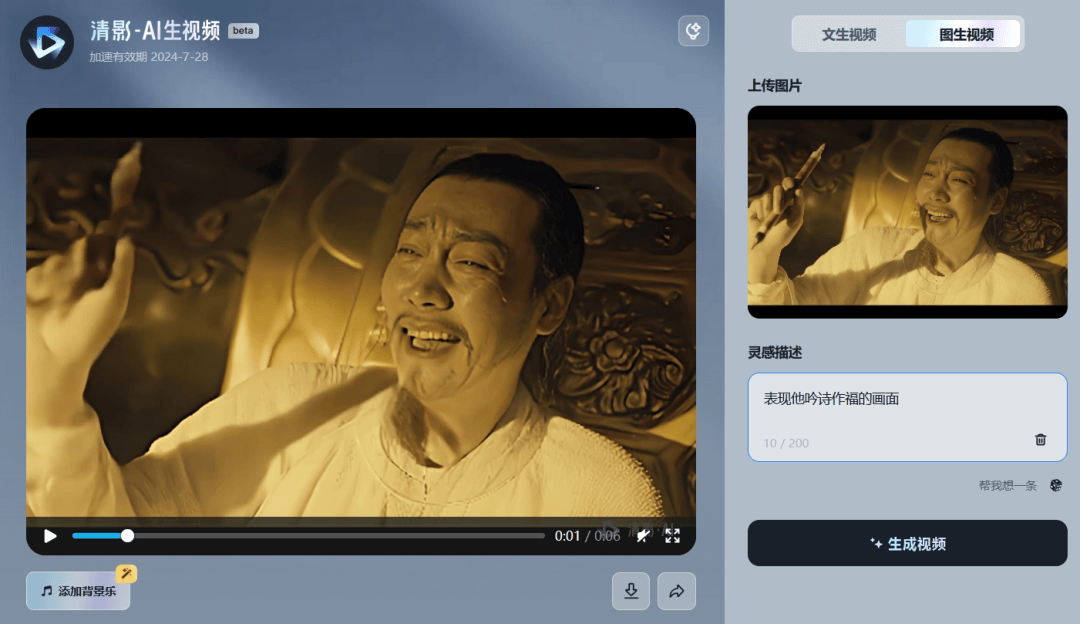
需要指出的是,除了文生视频外,清影还能实现图生视频,你给它一张图片,它就能给你生成一段视频。
陈凯歌导演的《妖猫传》中,有一个诗仙李白在宫廷里吟诗作赋的场景,让我记忆犹新,充分反映出了诗仙李白那惊世的才华,以及放荡不羁的气质。
接下来,我们就选取几张电影图片,来让清影生成视频。

下面是清影生成的视频。
下面这张,是我特别喜欢的。在这个场景中,李白看到一个绝世美人,作出了他的千古绝句。
《清平调》
作者:李白
云想衣裳花想容,春风拂槛露华浓。
若非群玉山头见,会向瑶台月下逢。

下面是清影生成的视频,从这个视频中,诗仙李白的痴狂被表现的淋漓尽致。
谁让诗仙李白这么陶醉呢?当然是倾国倾城的杨贵妃。中法混血女星张榕容扮演的杨玉环,的确很传神。

下面是清影生成的视频,在这个视频中,我给的指令是,“让她笑一笑,抛个媚眼”。
整体使用下来,感觉智谱AI此次发布的清影,还是挺强大的,不仅能够捕捉到指令中的关键元素,还能基于对整个文字内容的理解,来生成相应的视频。此外,图生视频也很有趣,相信会是引爆用户热情的一个重要抓手。
视频生成的核心技术是什么呢?
数据猿作为智能行业垂直专业媒体,只知其然不知其所以然,肯定是不够的。接下来,我们就来分析一下智谱清影背后的引擎——视频生成技术。
清影是前台的产品,而其技术核心,就是智谱AI的CogVideoX。
作为视频生成技术的最新突破,CogVideoX通过融合文本、时间和空间三个维度,实现了高效、连贯的视频生成。其采用DiT架构和优化算法,显著提升了推理速度和生成质量。CogVideoX不仅在技术上实现了突破,还为未来视频生成技术的发展提供了重要的方向和借鉴意义。
接下来,我们就用“显微镜”,来分析一下CogVideoX以及其所代表的视频生成技术。
既然视频生成的一个关键技术是DiT架构,那我们就先拿DiT“开刀”。
所谓DiT(DynamicI sometric Transformer)架构,是一种基于Transformer的模型架构,并强调动态(Dynamic)和等距(Isometric)的特性,它在视频生成任务中展现了强大的适应性和高效性。
所以,DiT有三个关键技术,分别是Transformer、Dynamic和Isometric。
Transformer模型由Vaswani等人在2017年提出,是一种基于自注意力机制(Self-Attention)的神经网络架构。自注意力机制是Transformer的核心,它通过计算输入序列中各个元素之间的相关性,使模型能够捕捉长距离依赖关系。
Transformer架构在处理序列数据时具有显著优势,例如,Transformer能够并行处理整个序列数据,克服了传统循环神经网络(RNN)和长短期记忆网络(LSTM)的计算瓶颈,提高了训练效率。而且,自注意力机制使得Transformer能够有效捕捉序列中远距离元素之间的依赖关系,特别适用于处理长序列数据。此外,Transformer的结构简单,易于扩展和优化,能够适应不同规模的数据和任务。
然而,Transformer的长处是在文字生成,其代表作就是ChatGPT。如果要生成视频,就需要对其进行改进。因此,在Transformer的基础上,DiT架构引入了动态性(Dynamic)和等距性(Isometric)的特性。
动态性指的是模型能够根据输入数据的不同动态调整其结构或参数,以更好地适应不同的任务需求,具体实现方法包括动态层选择和动态参数调整。根据输入序列的长度和复杂性,动态选择不同数量的Transformer层进行处理,从而在保证计算效率的同时提高模型的适应性。在训练过程中,模型根据输入数据的特点动态调整超参数,如注意力头的数量和隐藏层的维度,以优化模型性能。动态性的引入使得DiT架构在处理多样化的视频生成任务时更加灵活和高效,生成结果更加精确和符合需求。
等距性在DiT架构中指的是在处理空间数据时,保持图像或视频帧的几何一致性。这个特性对于视频生成尤为重要,因为视频生成需要在时间维度上保持帧与帧之间的连贯性,同时在空间维度上保持图像的统一性。等距性的实现主要通过空间注意力机制,在自注意力机制的基础上,确保在生成每一帧时,考虑到整个图像的全局信息,保持空间上的一致性。此外,通过引入位置编码和空间变换机制,使得每一帧在生成过程中都能够保留其空间结构和细节,确保最终生成的视频在视觉上连贯且自然。
CogVideoX,基于DiT,超越DiT。
上面提到过,CogVideoX是基于DIT,但并不局限于DIT,而是做了大量的优化工作。
CogVideoX视频生成模型在技术上实现了文本、时间和空间三个维度的深度融合,形成了高效且连贯的视频生成能力。其中,文本与视频生成的结合是CogVideoX的一大亮点。通过先进的自然语言处理技术,模型能够解析输入文本的语义,并生成与之高度一致的视频内容。这一过程涉及对文本的分词、语义分析和情感识别,确保生成的视频场景不仅在视觉上与文本描述匹配,还在情感和情景上高度契合。
在时间维度的处理上,CogVideoX采用了先进的时间序列建模技术。视频的本质是一系列连续的图像帧,因此时间序列的建模至关重要。CogVideoX捕捉视频帧之间的时间依赖关系,确保生成的视频在时间上的连贯性。
空间维度的处理是确保生成视频质量的另一关键点,CogVideoX保证每一帧图像的高质量和一致性。在生成过程中,模型通过对空间信息的处理,确保每一帧图像不仅细节丰富,还与前后帧保持一致。这样处理后的图像在视觉上连贯且自然,避免了图像扭曲和不一致问题。
需要指出的是,CogVideoX并不是一成不变的,而是处在快速的迭代演进当中。据悉,经过一系列的软硬件优化,CogVideoX在推理速度上相比前代模型CogVideo提升了6倍。这一显著的提升,不仅意味着更快的视频生成速度,还为生成更复杂和高质量的内容提供了可能。
视频生成的探索之路,才刚刚开始
需要指出的是,无论是OpenAI的Sora,还是智谱AI的CogVideoX,都只是视频生存的早期探索。接下来,视频生成模型会在高分辨视频、长视频、视频可精细化修改等方向,不断提升能力。
高分辨率视频生成,清晰度要越来越高。
高分辨率视频生成是视频生成技术发展的重要方向之一,但同时也面临诸多技术挑战。高分辨率视频生成,需要更强的计算能力和更大的存储空间。生成高分辨率图像的过程复杂度高,处理每一帧图像所需的计算资源大幅增加。因此,如何优化计算效率、减少资源消耗成为一个关键问题。
可能的解决方案包括采用更加高效的算法和硬件加速技术,例如,通过改进生成模型的结构,优化图像生成算法,可以减少计算复杂度。同时,利用分布式计算技术,将计算任务分配到多个处理单元并行处理,可以显著提升计算效率。此外,通过模型压缩,可以在保持生成质量的前提下,减少模型参数数量和计算资源需求,从而提高生成效率。
长时长视频生成,能达到影视剧的长度。
生成长时长视频需要处理长时间序列数据,这在技术上存在一定的难点。长时间序列数据处理要求模型能够捕捉和保持长距离依赖关系,而传统的时间序列模型在处理长序列数据时容易出现梯度消失或爆炸问题,导致生成质量下降。
在生成长时长视频时,保持模型的稳定性和一致性也是一个重要挑战。长时间的生成过程容易引入累积误差,导致生成内容的不一致。为此,可以采用一些技术手段来提高模型的稳定性。例如,利用生成对抗网络(GAN)中的判别器对生成的视频进行质量控制,确保每一帧图像的一致性和质量。此外,数据增强和正则化技术也可以在训练过程中引入,提高模型的泛化能力和稳定性。
多模态融合,将文本、图片、声音、视频、3D内容,融合起来。
多模态融合是视频生成技术的一个重要发展方向,通过将文本、音频、图像等多种数据类型进行融合,可以生成更加丰富和多样化的视频内容。未来的发展可以进一步探索多模态数据的深度融合,实现更高质量的生成效果。视频生成技术在虚拟现实、增强现实等新兴领域也具有广阔的应用前景,通过扩展应用场景,可以进一步提升技术的实际价值。
对生成视频的精细化修改,是接下来要攻克的一个关键挑战。
生成的视频不仅需要具备高质量,还要能够进行进一步的修改和精细化调整。这一需求主要来自于用户在实际应用中的多样化需求,通过提供强大的后期编辑功能,用户可以对生成的视频进行精细调整,包括颜色校正、细节增强、对象替换等。
实现精细化修改的技术挑战,在于如何在保持原有视频质量和连贯性的同时,进行局部的细节修改。可能的解决方案,包括基于深度学习的图像修复技术和视频编辑技术。例如,通过引入生成对抗网络(GAN)和卷积神经网络(CNN),可以实现对视频中局部区域的高质量修复和编辑。此外,结合计算机图形学中的物理模拟技术,可以对视频中的动态场景进行更真实的修改和渲染。
展望未来,视频生成技术的未来发展将对多个行业产生深远影响。
例如,在娱乐行业,视频生成技术可以大幅提高内容创作的效率和多样性,推动电影、电视、游戏等领域的发展。通过自动化视频生成,创作者可以更加专注于创意和故事情节的设计,而不必耗费大量时间在制作环节。视频生成技术在广告行业也有广阔的应用前景,通过生成个性化和定制化的广告内容,可以有效提升广告的吸引力和转化率。
让我们期待更多像智谱AI清影这样的视频生成模型,通过不断的技术创新和应用探索,为人们的生活带来更多便利和惊喜,推动社会的进步和发展。返回搜狐,查看更多
责任编辑:

蒋石磊:
8秒前:例如,利用生成对抗网络(GAN)中的判别器对生成的视频进行质量控制,确保每一帧图像的一致性和质量。
岡田義徳:
9秒前:接下来,我们就选取几张电影图片,来让清影生成视频。
山治:
4秒前:谁让诗仙李白这么陶醉呢?
康赵宇:
4秒前:作为一个大模型发烧友,有这样一款新奇的产品,当然是要第一时间去尝尝鲜。